背景
近期浏览某网站 PDF 电子书时,想保存到本地日后随时翻阅。右键审查元素后发现是 blob二进制存储方式,正规途径应该是通过 JS 脚本依次处理为 blob url->blob->base64,无奈十年前 JS就已经从入门到放弃了。只好研究出以下傻瓜式自动保存方式。
工具准备
- Chrome 浏览器
- Copy All Urls 插件 ( 下载地址)
- 按键精灵
- 任意文本编辑器
1、图片链接获取
打开相应电子书点击阅读按钮进入 PdfReader 阅读模式后,可一直向下滑动浏览完毕电子书(或直接打开按键精灵设置 Num↓ 按键循环 N 次)。
然后在 Chrome 浏览器下复制并打开 chrome://blob-internals/ 页面,下拉到最底部可以看到连续的全部的图片资源地址:blob:https://***********
2、链接格式处理
打开任意一个文本编辑器,将连续的图片资源地址复制进去,并将 blob 全部替换为 <br/>blob,然后将文件存为 .HTML 后缀格式。
之后点击文件或直接拖拽到 Chrome 浏览器后,就可以获取到分行的图片地址。
3、批量打开图片
上面获取到了分行的图片地址,全部复制后,在 Chrome 浏览器中点击 Copy All Urls 插件的 Paste 按钮后,稍等片刻插件会将每一个图片批量全部打开。
4、自动全部保存
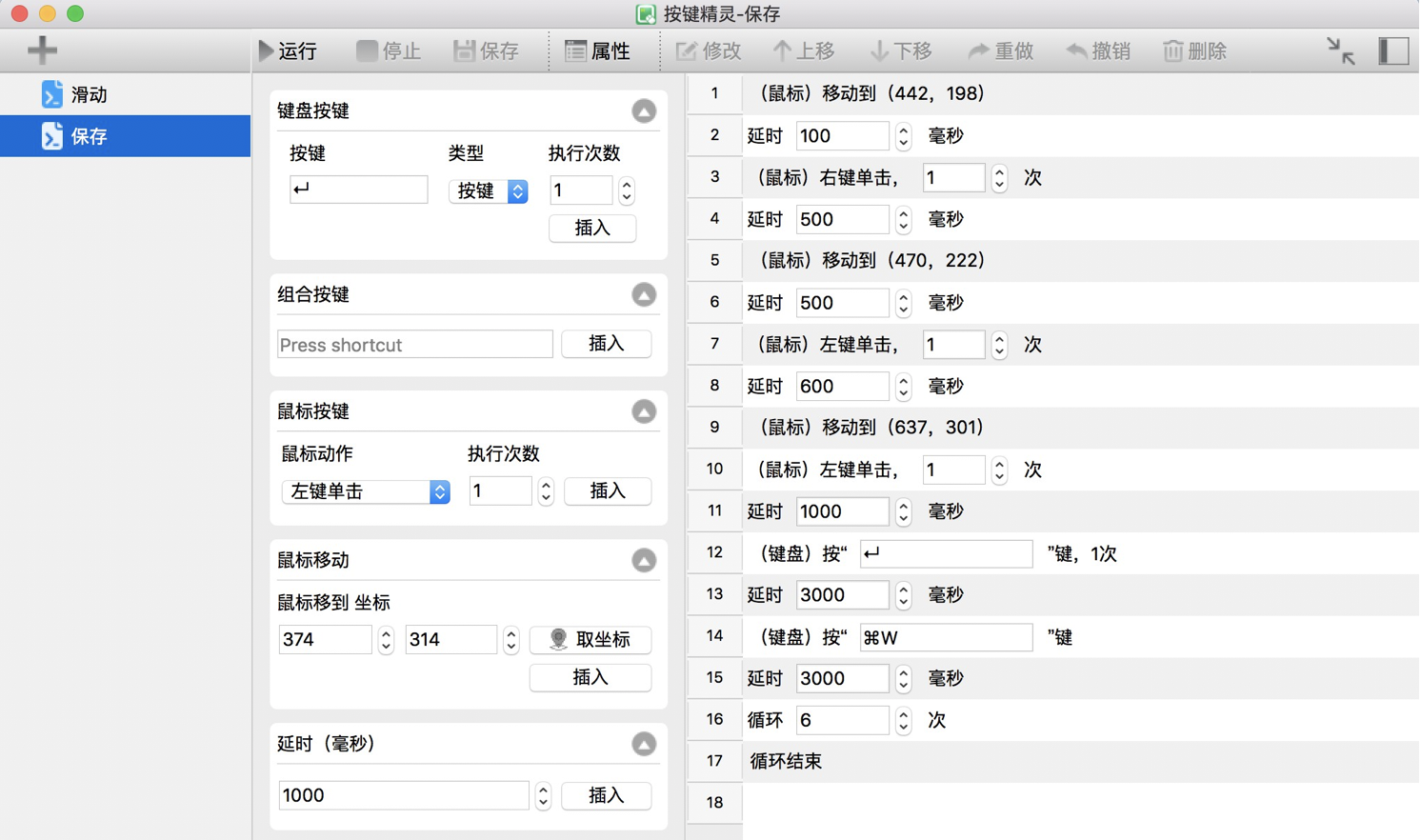
打开按键精灵,可按下图参考配置自动化脚本。这个脚本的本质其实就是把人工的「右键图片,选择保存图片,然后关闭标签页」的自动化执行。
备注:
1. 在 PdfReader 阅读模式下阅读完电子书后,保持当前标签页打开状态且不动,以保持图片链接资源不过期;
2. 最后一步按键精灵自动保存脚本中涉及坐标的定位,请以当前浏览器窗口为准重新获取对应位置。另外若有额外安装 Clear Downloads 自动清理下载插件可先关闭掉,因为 Chrome 浏览器下下载提示条会影响窗口坐标,需保持浏览器主体固定不变动。
3. 该保存方式适合 PDF 每页均为扫描图片类 PDF;
4. 头图来自《吉金耀采—院藏历代铜器》P30 蟠龙龙盘;
5. 以上仅供学习交流,严禁用于商业用途,如有下载相应资源请自觉于下载后24小时内删除。如家里有矿,请直接沟通正版实体书。